構建高效數據處理服務 項目規劃與實施指南
隨著企業數據規模的持續膨脹,數據處理服務已成為現代業務運營的核心支撐。一個精心規劃的數據處理項目,不僅能確保數據流的順暢與準確,更能為企業決策提供強有力的洞察。本文將系統性地闡述如何規劃與實施一個穩健、高效的數據處理服務項目。
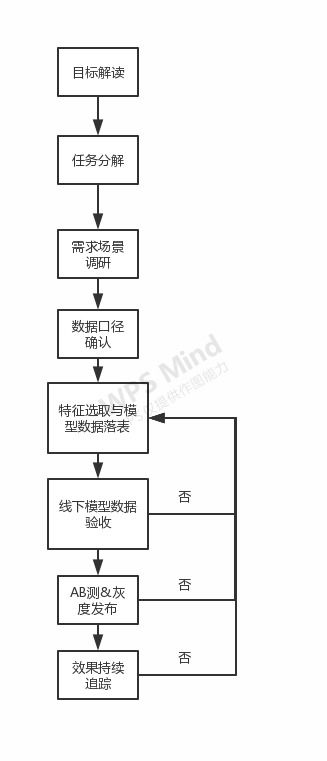
第一階段:需求分析與目標設定
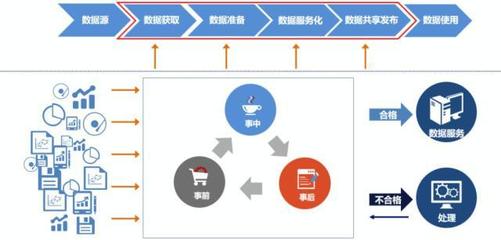
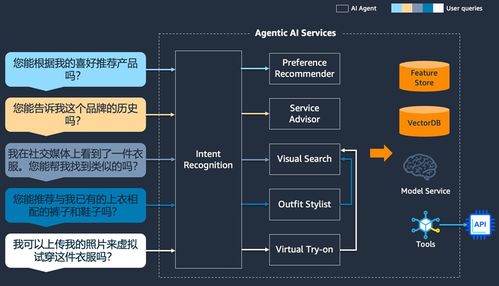
項目成功的基石在于清晰的需求定義。需要與業務部門深入溝通,明確數據處理的范疇:是實時流處理還是批量處理?數據來源包括哪些(如數據庫、日志文件、IoT設備)?處理后的數據將服務于哪些具體場景(如報表生成、用戶畫像、風險預警)?需設定可衡量的項目目標,例如將數據處理延遲降低50%,或實現99.9%的數據準確率。明確的范圍與目標是后續所有技術選型和架構設計的總綱。
第二階段:技術架構與工具選型
基于需求,設計數據處理的技術架構。核心通常包括數據采集、存儲、計算與輸出四大模塊。
1. 采集層:根據數據源特性,可選擇Apache Kafka、Flink CDC進行實時采集,或使用Sqoop、DataX進行批量同步。
2. 存儲層:需考慮數據湖與數據倉庫的搭配。原始數據可存入HDFS、S3等構建數據湖;處理后的結構化數據則可導入ClickHouse、Snowflake等數據倉庫,以供高效分析。
3. 計算層:這是核心處理引擎。對于批量ETL任務,Apache Spark以其強大的內存計算能力成為主流選擇;對于實時處理,Apache Flink提供了高吞吐、低延遲的流處理能力。
4. 調度與運維:采用Apache Airflow或DolphinScheduler對數據處理流水線進行可視化編排、調度與監控,確保任務依賴關系清晰、執行可靠。
選型時務必權衡團隊技術棧、社區生態、成本與性能,避免過度追求新技術而增加復雜度。
第三階段:詳細設計與開發實施
本階段將架構藍圖轉化為可執行代碼。關鍵任務包括:
- 數據流水線設計:定義每個處理步驟的輸入、輸出、轉換邏輯與容錯機制。例如,設計數據清洗規則以處理缺失值與異常值。
- 數據模型與Schema管理:設計目標數據模型,并建立嚴格的Schema演進協議,確保上下游兼容。
- 開發與測試:遵循模塊化開發原則,實現各處理單元。必須建立完備的測試體系,包括單元測試(驗證單個處理邏輯)、集成測試(驗證流水線銜接)和數據質量測試(驗證產出數據的準確性、完整性與一致性)。
第四階段:部署、監控與迭代優化
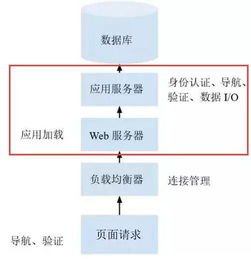
將開發完成的服務部署到生產環境(如Kubernetes集群),并配置完備的監控告警體系。監控應覆蓋:
- 資源層面:CPU、內存、磁盤IO使用率。
- 業務層面:數據處理延遲、吞吐量、任務成功率、數據質量指標(如重復記錄數)。
- 告警機制:當關鍵指標異常時,能及時通知運維人員。
項目上線并非終點。需建立常態化的性能評估與優化機制,例如通過數據傾斜優化、緩存策略、計算資源彈性伸縮等手段,持續提升服務效率與成本效益。
****
規劃一個數據處理服務項目是一項系統工程,貫穿業務、技術與運維。成功的核心在于以清晰的業務目標為導向,選擇穩健且匹配的技術棧,并在全周期貫徹嚴格的數據質量管控與持續的效能優化。通過上述四個階段的周密規劃與執行,企業能夠構建一個靈活、可靠的數據處理中樞,為數據驅動型決策奠定堅實基礎。
如若轉載,請注明出處:http://m.fgcktfhm.cn/product/2.html
更新時間:2026-05-06 02:56:09